内容にもとづいたアニメ推薦のための Contrastive Learning による埋め込み作成
創作+機械学習 Advent Calendar 2021 12日目の記事です。昨日は Xiong Jie さんの 超ニッチな二次元画像用リアルタイム超解像モデルを学習させた でした。
2022/11/11 追記: 本記事で紹介した技術がバンダイナムコグループで活用されています。
2022/1/10 追記: 本記事が優秀賞としてノミネートされ、賞金10,000円を頂きました!大切に使います💰 https://kivantium.hateblo.jp/entry/advent-calendar-2021-result
先に結論が知りたい人へ
以下のサイトにアクセスしてみてください。
はじめに
皆さんは新しくアニメを見ようと思った時にどのような基準で作品を選択するでしょうか?
一つの典型的なパターンとしては「Twitter のタイムラインでよくそのアニメの話題になっているから」というような、周りの口コミに頼ることがあるのではないかと思います。これは情報推薦の観点で考えると、近い属性のユーザーからアイテムを選択する Collaborative Filtering をしていることになります。
では、アイテムの中身にもとづいてアイテムを選択する Content-Based Filtering で見るアニメを決めることはできるのでしょうか。アニメの「中身」とはそもそも何か?という問いは哲学的ですらありますが、私は NLP(自然言語処理) の研究を行っている(しがない)学生なので、自然言語で書かれたあらすじが「中身」の指標の一つとなるのではないかと思いました。
例えば、異世界転生系アニメのあらすじは、どの作品でも質的に似ているような気がします。また、異世界転生系のアニメのあらすじと日常系アニメのあらすじは、質的に異なるような気がします。こうした内容の近さ/遠さをモデルに学習させることで、「あまり知名度は無いけれど内容が似た作品」 を探すのに役立つのではないかという期待ができます。
質的に近いアニメのデータセットを構築するのは難しいように思えますが、幸いなことに、アニメのドメインでは教師なしで擬似的なラベルを得ることが出来ます。それは 一期、二期... のようなシリーズ関係 です。例えば『響け!ユーフォニアム』の一期と『響け!ユーフォニアム』の二期の近さと、『響け!ユーフォニアム』の一期と『ゾンビランドサガ』の二期の近さを比べた時、前者が後者よりも内容的に近いのは明らかでしょう。
この記事では、東北大の日本語BERTをベースとして、上述したシリーズ関係のペアをもとに Contrastive Learning(対照学習) *1 を行うことでモデルを fine-tuning します。そのようにして作成されたモデルからは、作品のあらすじの内容の近さを反映した埋め込み(ベクトル)が得られます。さらに、この得られた埋め込みを簡単に確認できるようにするため、可視化用のウェブサイトを立てました。
このサイトを使うことで、似た内容と推測されるアニメを簡単に調べることができます。例えば下図は『無職転生 〜異世界行ったら本気出す〜』に似た内容の作品を調べている画面です。右側には埋め込みの距離が近い作品が列挙されていますが、異世界ものが多くを占めていることが分かるのではないかと思います。

内容にもとづいて次に見るアニメを決める際に是非役立ててみてください。
データセットの構築
今回の実験では
- 一期、二期... のようなシリーズ関係にある作品のあらすじのペア
- 各作品のあらすじのデータ
が必要になります。これらは Annict から抽出することができます。
抽出のために書いたコードを貼っておきます。
シリーズ関係にあるペアの抽出
シリーズ関係にある作品のペアを抽出するコード · GitHub
結果として 559 件のユニークなシリーズ関係の作品ペアが得られました。 データ(JSONL)のファイルの行は例えば以下のような感じになっています。
{
"arasuji1": ["喫茶店ラビットハウスへやってきたココア。", "うさぎの看板に釣られて入ったこのお店こそが、彼女が下宿することになる場所でした。", "リゼや千夜、シャロたちとすぐに仲良くなったココアはすっかり“木組みの街\"の一員に。", "ラビットハウスの一人娘であるチノのことは本当の妹のように可愛いがっています。", "そうして迎えた二度目の夏。", "今年もチノたちと、たくさんの思い出を作りたいココアですが、", "神妙な表情で、キャリーケースを持って駅のホームにたたずんでいます。", "ココアはいったいどこへ……?", "マヤとメグも遊びに来てくれて楽しい時間が流れますが、", "ココアが抜けてどこかちょっぴり賑やかさの足りないラビットハウス。", "そんな中、チノは少しだけ勇気を出して、みんなを花火大会に誘ってみることにしたのでした。"],
"arasuji2": ["ココアが木組みの街で過ごす", "二度目の夏ももうすぐ終わり、", "季節はイベント盛りだくさんの秋へと", "移り変わろうとしています。", "学校にもラビットハウスにも、", "楽しいことが今日もいっぱい!", "ココア、チノ、そしてみんなの未来へのわくわくが止まりません……!"]
}
これは後で訓練用と validation 用に split します。
各作品の抽出
こちらは埋め込みの作成対象である作品一覧を抽出するコードになります。劇場版アニメや OVA 等は除いて、テレビアニメのみを対象としました。
ここで1つ残念なことが分かったのですが、Annict であらすじが登録されている作品は最近のものに限られるようです。実際、抽出された 836 作品の放映時期の分布は以下のようになりました。
| 放映時期 | 作品数 |
|---|---|
| 2022 | 17 |
| 2021 | 186 |
| 2020 | 146 |
| 2019 | 152 |
| 2018 | 161 |
| 2017 | 93 |
| それ以前 | 81 |
もし、2016年以前のアニメのあらすじを効率的に集める方法をご存知の方がいらっしゃいましたら、是非コメント等で教えてください。
Contrastive Learning
有識者の方はご存知かと思いますが、BERT のような大規模言語モデルから直接得られる埋め込みはタスクの役には立たないことが多いです。例えば、NLP において基本的なタスクの1つである STS(Sentence Textual Similarity) タスクにおいてもそうで、パフォーマンスを出すためには NLI データセットを用いて明示的に似た意味の文のペアを学習させないといけません。*2
アニメのあらすじに関しても、単純に日本語 BERT に通して埋め込みを得るだけではうまくいかないと考えられます。そこで、Contrastive Learning を行って、明示的に似た内容の作品ペアを学習させます。
具体的には、ある作品とそのペアの作品とのスコアが、訓練バッチ内の他の作品とのスコアよりも大きくなるように学習します。図にすると以下のような感じになります。赤い矢印同士のスコアが、青い矢印同士のスコアよりも高くなるようにするということです。
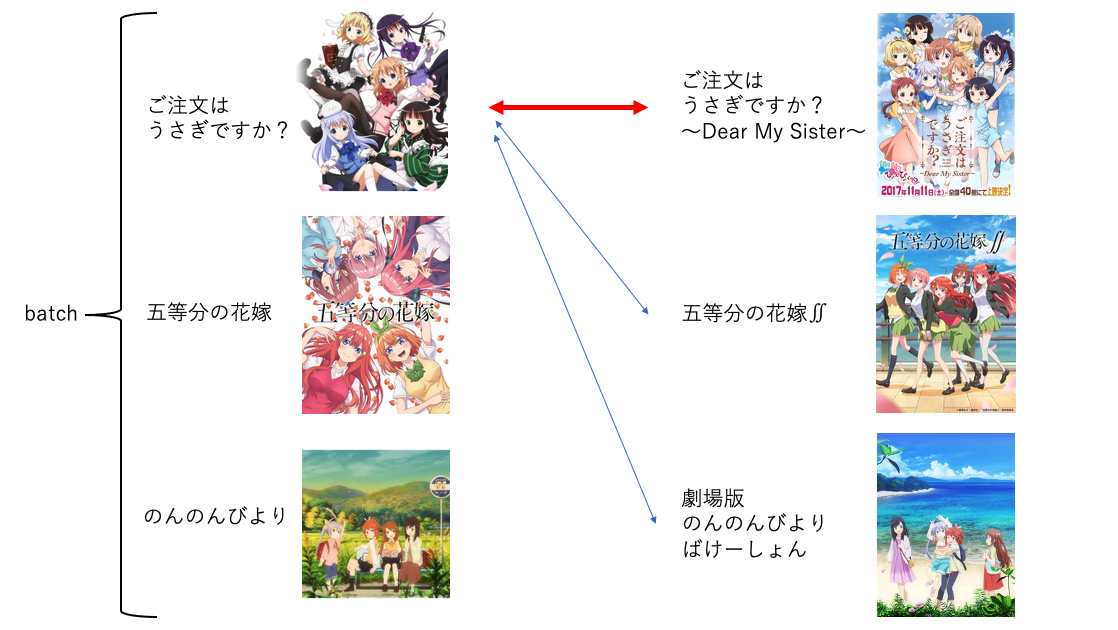
スコアの計算については、様々な流儀がありますが、今回は BERT の [CLS] トークンから得られる 768 次元の埋め込み同士の内積としました *3。
学習用コードは以下のようになります。
from accelerate import Accelerator from datasets import load_dataset import numpy as np import torch from torch.utils.data import DataLoader from transformers import AutoModel, AutoTokenizer, AdamW, default_data_collator, get_scheduler import argparse def main(args): accelerator = Accelerator() # データセットは shuffle 済みとする train_dataset = load_dataset('json', data_files=args.data_path, split='train[:90%]') valid_dataset = load_dataset('json', data_files=args.data_path, split='train[90%:]') tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking") model = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking") def tokenize_function(examples): # 文区切り, または改行区切りの文章に対して, 間に [SEP] を挟んで連結する sentences1 = ["[SEP]".join(ex) for ex in examples["arasuji1"]] sentences2 = ["[SEP]".join(ex) for ex in examples["arasuji2"]] tokenized_arasuji1 = tokenizer( sentences1, padding='max_length', max_length=512, truncation=True, ) tokenized_arasuji2 = tokenizer( sentences2, padding='max_length', max_length=512, truncation=True, ) outputs = {} outputs["arasuji1_input_ids"] = tokenized_arasuji1["input_ids"] outputs["arasuji1_token_type_ids"] = tokenized_arasuji1["token_type_ids"] outputs["arasuji1_attention_mask"] = tokenized_arasuji1["attention_mask"] outputs["arasuji2_input_ids"] = tokenized_arasuji2["input_ids"] outputs["arasuji2_token_type_ids"] = tokenized_arasuji2["token_type_ids"] outputs["arasuji2_attention_mask"] = tokenized_arasuji2["attention_mask"] return outputs tokenized_train_dataset = train_dataset.map(tokenize_function, remove_columns=["arasuji1", "arasuji2"], batched=True) tokenized_valid_dataset = valid_dataset.map(tokenize_function, remove_columns=["arasuji1", "arasuji2"], batched=True) train_dataloader = DataLoader( tokenized_train_dataset, batch_size=8, collate_fn=default_data_collator ) valid_dataloader = DataLoader( tokenized_valid_dataset, batch_size=8, collate_fn=default_data_collator ) optimizer_grouped_parameters = [ { "params": [p for n, p in model.named_parameters()], "weight_decay": 0.0, }, ] optimizer = AdamW(optimizer_grouped_parameters, lr=5e-5) model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare( model, optimizer, train_dataloader, valid_dataloader ) num_update_steps_per_epoch = len(train_dataloader) max_train_steps = args.num_train_epochs * num_update_steps_per_epoch lr_scheduler = get_scheduler( name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=max_train_steps, ) for epoch in range(args.num_train_epochs): model.train() for step, batch in enumerate(train_dataloader): arasuji1_outputs = model(**{ "input_ids": batch["arasuji1_input_ids"], "token_type_ids": batch["arasuji1_token_type_ids"], "attention_mask": batch["arasuji1_attention_mask"] }) arasuji2_outputs = model(**{ "input_ids": batch["arasuji2_input_ids"], "token_type_ids": batch["arasuji2_token_type_ids"], "attention_mask": batch["arasuji2_attention_mask"] }) arasuji1_embeddings = arasuji1_outputs[1] # take [CLS] embeddings arasuji2_embeddings = arasuji2_outputs[1] # take [CLS] embeddings scores = arasuji1_embeddings.mm(arasuji2_embeddings.t()) # contrastive learning bs = scores.size(0) target = torch.LongTensor(torch.arange(bs)) target = target.to("cuda:0") loss = torch.nn.functional.cross_entropy(scores, target, reduction="mean") accelerator.backward(loss) optimizer.step() lr_scheduler.step() optimizer.zero_grad() model.eval() eval_accuracy = 0.0 nb_eval_examples = 0 for step, batch in enumerate(valid_dataloader): arasuji1_outputs = model(**{ "input_ids": batch["arasuji1_input_ids"], "token_type_ids": batch["arasuji1_token_type_ids"], "attention_mask": batch["arasuji1_attention_mask"] }) arasuji2_outputs = model(**{ "input_ids": batch["arasuji2_input_ids"], "token_type_ids": batch["arasuji2_token_type_ids"], "attention_mask": batch["arasuji2_attention_mask"] }) arasuji1_embeddings = arasuji1_outputs[1] # take [CLS] embeddings arasuji2_embeddings = arasuji2_outputs[1] # take [CLS] embeddings scores = arasuji1_embeddings.mm(arasuji2_embeddings.t()) bs = scores.size(0) scores = scores.detach().cpu().numpy() predictions = np.argmax(scores, axis=1) target = torch.LongTensor(torch.arange(bs)).detach().cpu().numpy() tmp_eval_accuracy = np.sum(predictions == target) eval_accuracy += tmp_eval_accuracy nb_eval_examples += arasuji1_embeddings.size(0) normalized_eval_accuracy = eval_accuracy / nb_eval_examples print(f"epoch {epoch}: {normalized_eval_accuracy}") accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(f"output_epoch{epoch}", save_function=accelerator.save) if accelerator.is_main_process: tokenizer.save_pretrained(f"output_epoch{epoch}") if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("--data_path", type=str, required=True) parser.add_argument("--num_train_epochs", type=int, default=20) args = parser.parse_args() main(args)
手元で動かしてみたところ、4回目のepochで一番 validation accuracy が高くなったので、これを埋め込みモデルとします。
埋め込みの生成とウェブサイトのホスティング
モデルが作成されたところで、今度は、Annict にあらすじが登録されている 836 作品の埋め込みを作っていきます。これは、後でウェブサイトの形式に合わせるため TSV で保存します。
import torch from tqdm import tqdm from transformers import AutoModel, AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("./trained_model") model = AutoModel.from_pretrained("./trained_model") model.eval() import json with open("annict_data.jsonl", "r") as fi, \ open("embeddings_meta.tsv", "a") as fo1, \ open("embeddings.tsv", "a") as fo2: fo1.write("name\tseason\n") with torch.no_grad(): for line in tqdm(fi.readlines()): anime_data = json.loads(line) fo1.write(f"{anime_data['タイトル']}\t{anime_data['時期']}\n") arasuji_sentence = "[SEP]".join(anime_data["あらすじ"]) inputs = tokenizer.encode_plus( arasuji_sentence, padding='max_length', max_length=512, truncation=True, return_tensors="pt" ) outputs = model(**inputs) embeddings = outputs[1][0].detach().cpu().numpy() embeddings_str = [str(e) for e in embeddings] embeddings_str_concat = "\t".join(embeddings_str) fo2.write(f"{embeddings_str_concat}\n")
埋め込みの可視化サイトには https://github.com/tensorflow/embedding-projector-standalone を使います。これは既に github pages の形式になっているので、フォークして自分が作った埋め込みを代わりに載せてあげるだけで可視化ができ、とても便利です。
埋め込みの観察
では、作成された埋め込みを実際に見ていきましょう。
まず、全体を UMAP で可視化すると、2つの大きな塊群に分かれているように見えます。
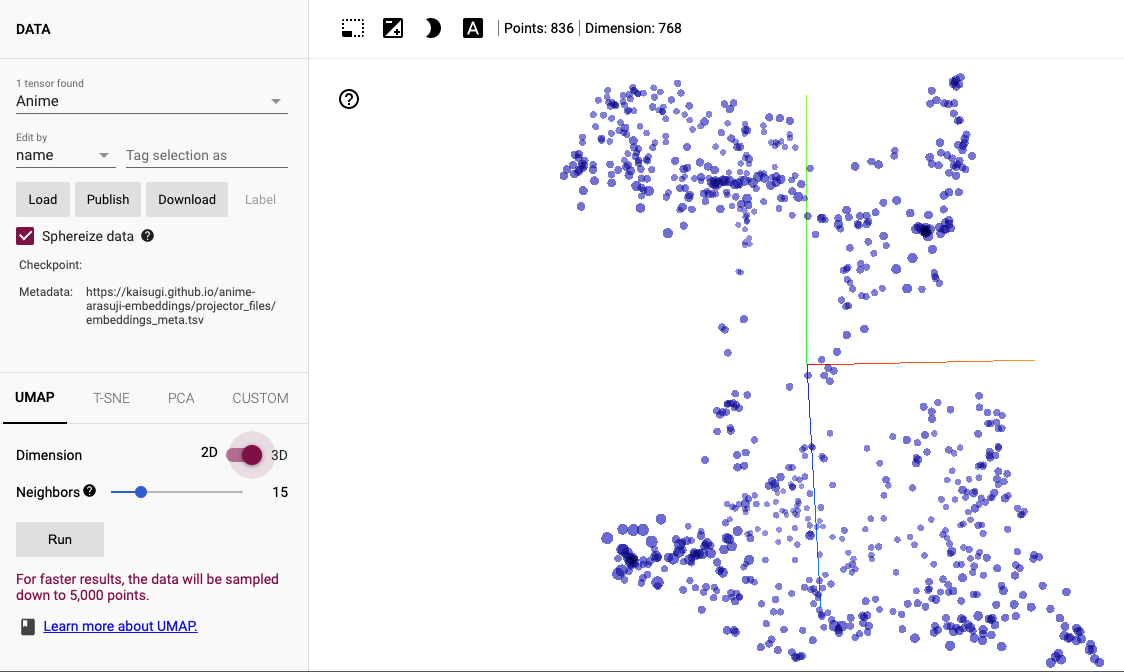
はっきりとした確証は持てていないのですが、自分の予想としては「日常系」作品と「非日常系」作品に分離しているのではないかと思っています。「日常系」作品のあらすじの方が「ゆるふわ」な言葉遣いであらすじが書かれている傾向にあることを考えれば、これは自然です。
具体的に近いアニメを探したい場合は、点をクリックすればよいです(Search のところから直接アニメのタイトルを検索することもできます)。
いくつか自分が知っている作品で調べてみます。

『ウマ娘 プリティーダービー』に最も近い作品は、シリーズ関係のものを除くと、『つうかあ』になりました。『つうかあ』はレーシングが題材のアニメなので、上手くサジェストできていると言えるでしょう。他にもアイマス関係が出てくるのも割と妥当な気がします。
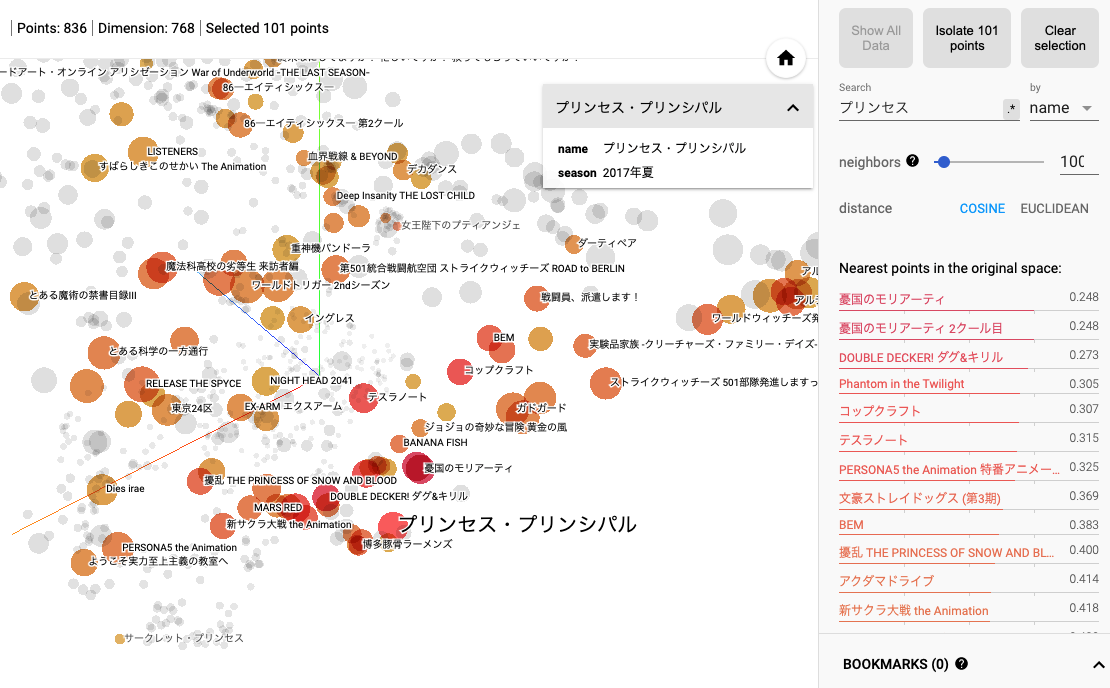
『プリンセス・プリンシパル』に近い作品としては、『憂国のモリアーティ』『DOUBLE DECKER! ダグ&キリル』『Phantom in the Twilight』などがサジェストされました。これらはいずれも、異国での探偵やスパイに関連する作品であり、内容にもとづいた推薦を行っていると言えそうです。
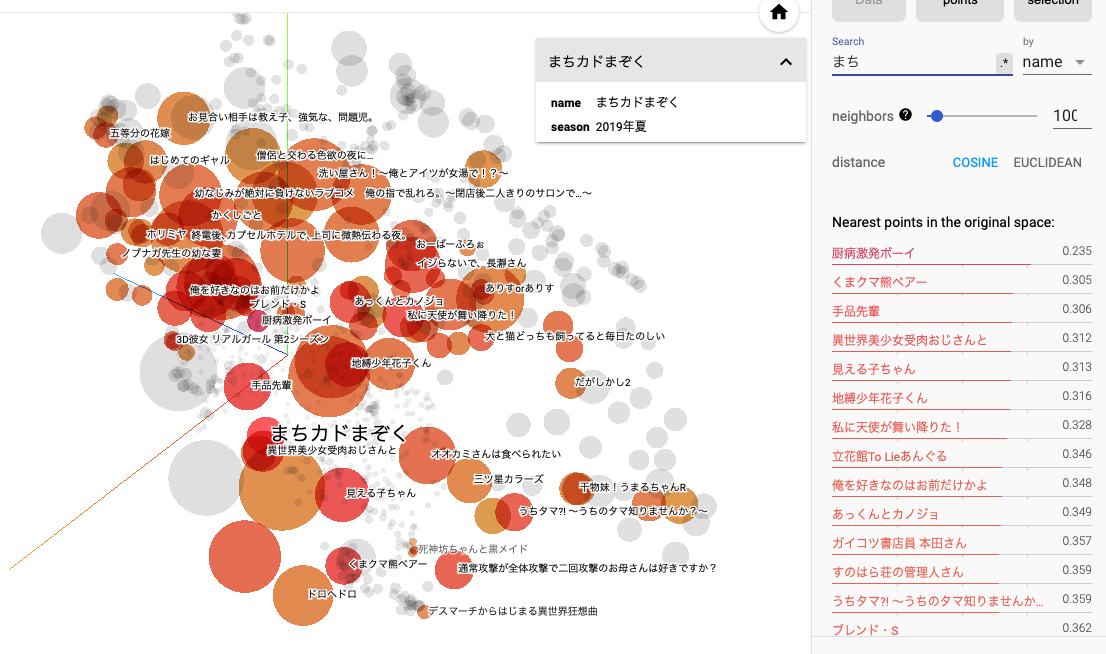
『まちカドまぞく』に近い作品としては、『厨病激発ボーイ』『くまクマ熊ベアー』『手品先輩』などがサジェストされました。全然知らない作品ばかりなので何もコメントできないのですが、一風変わった設定の日常系、くらいの共通項はあるのでしょうか...。
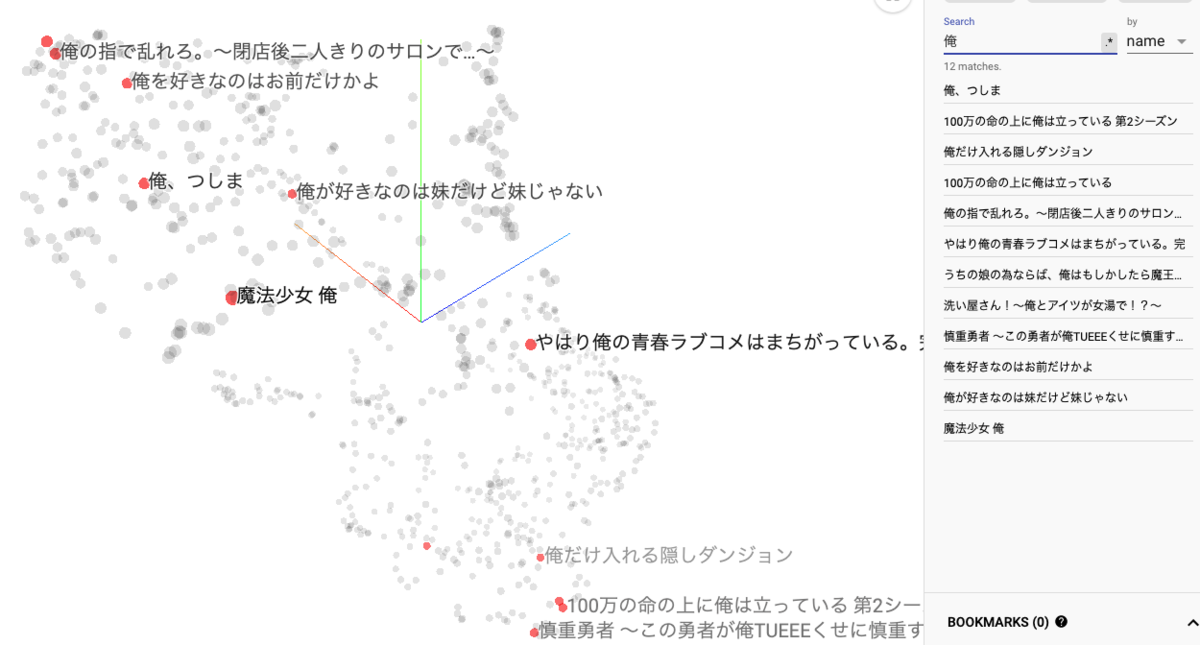
他にも、特定の文字をタイトルに含んだアニメだけに絞って埋め込みを観察するのも面白いです。例えば、以下は「俺」をタイトルに含むアニメの埋め込みを比較したものですが、質的な違いが相当あることが見てとれます(上の方が恋愛もの、下の方がなろう系。『俺ガイル』が真ん中あたりにあるのが面白いですね)。
おわりに
この記事では、機械学習を活用し、内容にもとづいて次に見るアニメを決める方法を紹介しました。あらすじはアニメの中身の要素のごく一部に過ぎませんが、一つの良い指標になるのではないかなと思います。
今は 2016 年以前の作品のあらすじをほとんど集められていませんが、今後も継続的にデータを増やして、より推薦候補作品を充実させていこうと考えています。