Misskeyの投稿をX(旧Twitter)にも自動で投稿できるようにする(2023年10月版)
X(旧Twitter)を使う機会が減りつぶやき一覧が寂しいことになっていたので、普段使っている Misskey の投稿を自動でそのままポスト(ツイート)できるようにしてみました。
Misskey には Webhook 機能が用意されており、これを使うと自分の Misskey の投稿を subscribe することができます。
これをもとに、何らかの FaaS を使えばX(旧Twitter)への自動投稿が実現できます。自分は仕事で Google Cloud に慣れているので、Google Cloud の FaaS である Cloud Functions を使います。
ただし、Misskey、X(旧Twitter) 双方ともに API の仕様が今後もコロコロ変わると思うので、あくまで現在(2023年10月)の情報だと思ってお読みください。
Misskey の Webhook の設定
https://misskey.io/settings/webhook から Webhook を登録します。Webhookを実行するタイミングを「ノートを投稿したとき」に絞っておきます。
また、安全な鍵を事前に作成しておいて「シークレット」に登録しておきます。これは、後で Webhook のリクエストヘッダーから X-Misskey-Hook-Secret という名前で取得することができます。
あとで Cloud Functions の関数を作ったら、その URL をこちらに設定しておきます。
X(旧Twitter) のAPIの設定
以下の記事を参照してアクセストークンおよび refresh token を発行します。
また、CLIENT_ID、CLIENT_SECRET は Cloud Functions の関数を作る際にも必要になるため控えておきます。
Cloud Storage の設定
現行の Twitter API v2 ではアクセストークンに有効期限(2時間)が設定されており、refresh token を使ってアクセストークンを更新する作業が必須になります。これにどう対処するかが今回大きな問題になりました。
あまり褒められた実装ではないとは思うのですが、Cloud Functions の関数実行時に、アクセストークンを毎回前もって更新することにしてみます。
更新が必要ということは stateful なアクセストークンと refresh token の値が必要ということになりますが、Cloud Functions のような FaaS は stateless なので、何らかの場所にこれらの状態を保管しておかねばなりません。
そこで今回は、Cloud Storage にバケットを作成しておき、そこに
{ "access_token": "XXXXXXXXXXXXX", "refresh_token": "YYYYYYYYYYYYY" }
という形式の tokens.json というファイルを置くことにしました。最初の1回はここは人手でやる必要があります。
合わせて、新規にサービスアカウントを作って、roles/storage.admin を付与します。このサービスアカウントを、後で Cloud Functions を作る時にランタイムに割り当てます。これをやらないと、Cloud Functions から Cloud Storage のファイルへ読み書きができません。
Cloud Functions の関数の作成
Twitter の API を叩くのはそこまでレイテンシのある操作ではないので、特に Pub/Sub を挟まずに Cloud Functions 一本書きでやります。
関数を作成する際には、環境変数として
MISSKEY_HOOK_SECRET: 先ほど言及した Misskey の Webhook のシークレットTWITTER_CLIENT_ID: Twitter の CLIENT_IDTWITTER_CLIENT_SECRET: TWITTER の CLIENT_SECRETCLOUD_STORAGE_BUCKET: 先ほど作成した Cloud Storage のバケット名
を設定しておきます。本当は Google Cloud ではこの種の変数は Secret Manager で管理した方がよいですが、お遊びのプロジェクトなので環境変数に入れてしまいます。
関数は、以下のように書いてみました。
import functions_framework from google.cloud import storage import os import requests from requests.auth import HTTPBasicAuth import json MISSKEY_HOOK_SECRET = os.getenv('MISSKEY_HOOK_SECRET') TWITTER_CLIENT_ID = os.getenv('TWITTER_CLIENT_ID') TWITTER_CLIENT_SECRET = os.getenv('TWITTER_CLIENT_SECRET') CLOUD_STORAGE_BUCKET = os.getenv('CLOUD_STORAGE_BUCKET') @functions_framework.http def main(request): storage_client = storage.Client() bucket = storage_client.bucket(CLOUD_STORAGE_BUCKET) headers = request.headers req_secret = headers.get('X-Misskey-Hook-Secret') if req_secret != MISSKEY_HOOK_SECRET: return "Invalid Secret", 403 data = request.get_json() text = data["body"]["note"]["text"] visibility = data["body"]["note"]["visibility"] replyId = data["body"]["note"]["replyId"] renoteId = data["body"]["note"]["renoteId"] fileIds = data["body"]["note"]["fileIds"] if text is None: return "No Content", 204 if visibility != "public": return "No Content", 204 if replyId is not None or renoteId is not None: return "No Content", 204 if fileIds != []: return "No Content", 204 try: new_access_token = update_twitter_access_token(bucket) res = tweet(text, new_access_token) print("Successfully tweeted!") print(res) return "OK", 200 except Exception as e: print(e) return "Internal Server Error", 500 def tweet(text, access_token): url = "https://api.twitter.com/2/tweets" payload = { "text": text, "reply_settings": "mentionedUsers" } headers = { "Authorization": f"Bearer {access_token}", "Content-Type": "application/json" } res = requests.post(url, data=json.dumps(payload), headers=headers) return res.json() def update_twitter_access_token(bucket): blob = bucket.blob("tokens.json") old_tokens_data = json.loads(blob.download_as_text()) old_refresh_token = old_tokens_data["refresh_token"] url = "https://api.twitter.com/2/oauth2/token" payload = { 'refresh_token': old_refresh_token, 'grant_type': 'refresh_token', 'client_id': TWITTER_CLIENT_ID, } headers = { 'Content-Type': 'application/x-www-form-urlencoded', } res = requests.post(url, headers=headers, data=payload, auth=HTTPBasicAuth(TWITTER_CLIENT_ID, TWITTER_CLIENT_SECRET)) res_json = res.json() new_tokens_data = { "access_token": res_json["access_token"], "refresh_token": res_json["refresh_token"] } blob.upload_from_string(json.dumps(new_tokens_data)) print("Successfully updated tokens!") return res_json["access_token"]
今回は、Misskeyの投稿のうち
に限って自動投稿する設定にしています。さらに、投稿の際に "reply_settings": "mentionedUsers" というオプションを付けることで、リプライ不可能なツイートに設定しています。
還付申告をした話
あらすじ
今朝、自宅に「年調未済 普通徴収B」なる摘要が書かれた源泉徴収票が届いたので、還付申告により源泉徴収額分の金額を取り戻しました。
自分は確定申告を人生でまだしたことがなかったので、記念にメモを書いておきます。
還付申告とは
還付申告とは、本来確定申告の必要のない人などが、納め過ぎた税金の還付を目的に行う確定申告です。
なぜ還付申告が必要になったのか
私は給与が130万円の壁を突破していないので、本来であれば所得税を払う必要のないはずの学生です。
そもそも2023年1月現在の情報において130万円の壁というのが何なのかを説明すると、
- 給与 S 円が S ≤ 1,625,000 を満たす(★)場合、給与所得は S - 550,000 円になる。
- アルバイト給与以外の方法でお金をもらっていない場合、所得合計も S - 550,000 円になる。これは★より 24,000,000 円以下であるという条件を満たすので、基礎控除 480,000 円が所得控除として受けられる。
- さらに学生であれば勤労学生控除 270,000 円が所得控除として受けられる。
- 以上より、(S - 550,000) - 480,000 - 270,000 = S - 1,300,000 円 に対して所得税が計算されるので、S が 130 万円以下であれば所得税は発生しない。
しかしながら、今日届いた源泉徴収票では「年調未済」という旨のもと、数百円の徴収がされていました。このお金は研究室の雑用をした時にもらった給与(1万円程度)に対して発生しているのですが、口座の記録を振り返ってみると、源泉徴収をあらかじめされた状態で口座に入っていました。
本来であれば、源泉徴収票は全て年末調整の時にまとめて提出し、所得税が0円であることが決まるはずです(実際、他の経路のバイト給与ではそうしています)。
ということは今日届いた源泉徴収票で徴収されているお金は取り返せるはずです。
還付申告をやる
還付申告というのは確定申告の一種なので、確定申告作成ページからやっていきます。
必要なものは源泉徴収票とマイナンバーカードです。源泉徴収票は、年末調整をきちんと行った結果のものと、「年調未済」のもの、両方を用意しておきます。
一通り記入が終わると還付金が表示されます。やったー!

今後に向けて
今年度は業務委託で収入を得ているので、事業所得が発生しており、来年に確定申告をしないといけない人間になります。なので今年のうちに確定申告を体験できてよかったです。
子供部屋おじさんを卒業する
一人暮らし Advent Calendar 2022 2日目の記事です。昨日はてってけ氏さんの ガスのない生活3年目の冬を迎えるにあたっての所感 でした。
来年から社会人になる予定の修士課程2年の者です。
大学が家から(ギリギリ)通える範囲にあったため、これまで大学・大学院生活を通じて子供部屋おじさんとして過ごしてきました。しかし、実家暮らしでは生活能力がいつまでも身につかないという危機感や、親からの早く子供を追い出したいという無言のプレッシャーなどがあり、先月11月に人生初めての引越しを行いました。
引越しに関するあれこれを全て自力で行う必要がありましたが、幸いにも、先人達が残してきた数々のブログ記事のおかげで問題なく遂行することができました。これらに感謝の意を表し、私も何らかの情報を残せればと思い、筆を取ることにしました。
スケジュール
内定先の条件から勤務地が東京であることは何となく分かっていましたが、10月の面談で東京であることが確定したので、そこから引越しのことを本格的に考え始めました。
通常、修士了で新卒から一人暮らしを始める場合、修論発表などが終わった後の2月以降に動き出すパターンが多いのではないかと思います。しかし、先人達の情報を見ると、2月からではなかなか良い物件が見つからないのではないかという気がしました。また、ある程度の貯金はあったので、数ヶ月は親に資金を頼らずに何とか乗り切れるのではないかと判断しました(実際には、かなりスレスレの家計水準を歩んでいるので、オススメはしません)。
そこで自分の場合、11月初頭に内見を行い即契約し、下旬に引っ越しを完了させました。
物件の条件
以下のような条件で探しました。
- 某都内沿線の某駅or某駅or某駅 15分以内
- リモート勤務が主体の職業なので、以前は千葉の遠方に住むことも考えていたのですが、自分より少し前に都内で一人暮らしを始めた知人に感化されて都内にしました。結果的には都内で毎日一人で暮らして楽しいので大正解です。
結婚できない男
- リモート勤務が主体の職業なので、以前は千葉の遠方に住むことも考えていたのですが、自分より少し前に都内で一人暮らしを始めた知人に感化されて都内にしました。結果的には都内で毎日一人で暮らして楽しいので大正解です。
- 管理費・共益費込みで家賃月6.5万以内
- 労働条件通知書に書かれた初任給に0.8をかけて3で割る(「手取りの3分の1」の概算)と自分はこの位になりました。実際には家賃補助も出るのでもっと払えるのですが、6.5万で見た物件で自分は十分でした。そのくらい、実家の子供部屋が狭すぎました。
- 面積15m2以上
- 子供部屋が15m2くらいだったので、これより狭いと引っ越す意味があまりない気がしました。
- 築30年以内
- これを超えると今の建築基準に沿わない物件がちらほら出てきます。あと欲を言えば20年以内くらいがいいなとは内心思っていました。今の物件は20年弱ですが十分綺麗に感じます(内見しないとこういうことは分かりません)。
- 2階以上
- 1階だと虫が出やすい話をよく見たためです。また、今の物件がそうなのですが、単純に階数が高い方が朝起きた時に眺めが良くて気分が上がります(ただし、景観はやはり内見しないと分からないです)。
- 光回線
- フレッツ光が使えるかを https://flets.com/app2/cao/index/index/ で確認しましょう。不動産屋でもらう物件のチラシには、フレッツ光対応済みである場合明記されていることもあります。自分は最初から書いてある物件にしたので安心でした。
- エアコン付き
- 何だかんだ冬の今は毎日鍋作ってるので使ってないです。夏は流石に必要だと思います。
- 室内洗濯機置場
- コインランドリー生活は2日で諦めました。
- 北向きでないこと
- 実家の子供部屋が北向きで劣悪な環境でした。
- 鉄筋・鉄骨
- 木造は逆にあまりない気がするのですが。
- 初期費用をカードで分割払いできること
- 一般的に初期費用は高いです。家賃の5倍と見ておくべきです。今の物件はたまたま敷金礼金無しでしたがそれでも家賃の3倍はかかります。初任給が入る4月(人によっては5月)まで期間がある場合、手数料は覚悟で、分割払いにして少しでも払う金額を4月以降に回すと良いと思います。ちなみに、私の行った不動産屋の物件は全て初期費用カード払いに対応していました。
Note: 物件の条件について引っ越した後に思ったこと
- 特に条件に入れていませんでしたが、オートロック物件は良いと住んでいて思います。外から虫が入りにくいですし、(一人暮らしの女性が多いからか)全体的に静かです。
- バス・トイレ別は条件に含めるか迷い、結局諦めましたが、ユニットバスには住んでいてすぐに慣れました。ただ、汗を書く運動が好きで、家で湯船に浸かりたい、みたいな人はやはりバス・トイレ別の方が良いと思います。
- 何だかんだ一番気に入ってるのは、近隣の住宅環境です。SUUMOを眺める時間も必要ですが、最終的には内見で家の周りの雰囲気を掴むのが本質だと思います。
不動産屋訪問 & 内見 & 申し込み
以上のような条件でSUUMOで物件を調べ、一番良さそうな物件を見つけました。おとり物件ではないことを裏取るために、その物件が複数の不動産業者から情報提供されていることを確認しました。その上で、その物件の情報を出している不動産業者のうち最も Google レビューの評価の高い不動産屋に行きました。
不動産屋では、私が見つけていた物件の他に、条件を満たす物件のチラシを多数渡されました。それらのチラシを見てもあまりピンと来なかったのですが、実際に内見してみると全然違いました。私がSUUMOで良いと思っていた物件は薄暗くジメジメした部屋で、逆に不動産屋がオススメする物件は開放的で、すぐに気に入りました。さらに、全く同じタイミングで別の人が内見していたので、モタモタしていると取られそうだという気がしました。結局その日に申し込みを入れることにしました。
結果論として今の物件は気に入ってるので良かったのですが、実際はもう少し慎重に複数の不動産屋に行って比較検討するとさらに良いと思います(私は多忙な学生だったのでそこまではできませんでした)。
引越しまでにやること
- 粗大ゴミの処分(自治体に回収してもらう場合、受付に多少の時間がかかる場合があるので、早めに申し込んでおくとよし)
- 荷物の段ボール詰め
- 転出届
- 転居・転送サービスの申し込み(これも、郵便を転送してくれるまで数日かかる場合があるので、早めに申し込むべし)
引越し
単身パックを使います。
新居での手続き
水道
特に難しいことはありません。東京都はWeb上で申し込みができます。
電気・ガス
東京ガスで一括にしました。ガスだけは開栓立ち合いが必要ですが、立ち合いの予約変更にも親切に応じてくれて大変助かりました。
インターネット
フレッツ光物件であってもNTT東西から契約する必要はありません。光コラボ事業者で契約すると導入費用が安くなることが結構あります。
私はドコモ光 + GMOとくとくBBにしました。
IPv6対応ルータも無料で借りれるので結構オススメです。今の物件では200〜500Mbps程度出ています。ただし携帯回線がドコモ(またはahamo)である必要があるので、トータルの金額では他の選択肢よりやや高いかもしれません。
新居に移った後にやること
- 転入届
- マイナンバーカードの住所変更
- 運転免許証の住所変更(東京都では都内のどの警察署でもできます)
- バイト先などへの住所変更届の提出
まとめ
引越しの作業は、書いてみると意外とシンプルだなと改めて思います。
ただ、実際にはハプニングも付き物で、計画通りにうまくいかないことも多いでしょう。
例えば私は、引越しの当日に(!)急性胃腸炎で倒れました。駅で寝込み、病院で薬を処方された後、数回下痢をしながら新居に手荷物を持ってたどり着き、そのまま2日ほど寝込みました。おかげで引越し作業が想定よりも遅れてしまいました。家の近くのドンキホーテで布団セットが買えなかったり、UberEatsで食事などが頼めなかったりしたら、もっと大変だったと思います。あの日ほど人生にパートナーが必要だと思った日はなかなか無い
それでも、引っ越した後の今は、子供部屋にいた頃よりもずっと快適に暮らせています。子供部屋よりも集中して論文が書けていますし、研究室にオンサイトで行く場合にも電車に乗る時間が大幅に減りました。生活において、自炊をする楽しみもできました。
今後社会人になる子供部屋おじさん/おばさんの方も、もし多少の金銭的余裕があれば、ひと足先に子供部屋おじさん/おばさんを卒業してみるというのはいかがでしょうか。
参考文献
最後に、引越しをするにあたって大変参考になった過去のブログ記事をまとめて紹介します。皆さんありがとうございました。
内容にもとづいたアニメ推薦のための Contrastive Learning による埋め込み作成
創作+機械学習 Advent Calendar 2021 12日目の記事です。昨日は Xiong Jie さんの 超ニッチな二次元画像用リアルタイム超解像モデルを学習させた でした。
2022/11/11 追記: 本記事で紹介した技術がバンダイナムコグループで活用されています。
2022/1/10 追記: 本記事が優秀賞としてノミネートされ、賞金10,000円を頂きました!大切に使います💰 https://kivantium.hateblo.jp/entry/advent-calendar-2021-result
先に結論が知りたい人へ
以下のサイトにアクセスしてみてください。
はじめに
皆さんは新しくアニメを見ようと思った時にどのような基準で作品を選択するでしょうか?
一つの典型的なパターンとしては「Twitter のタイムラインでよくそのアニメの話題になっているから」というような、周りの口コミに頼ることがあるのではないかと思います。これは情報推薦の観点で考えると、近い属性のユーザーからアイテムを選択する Collaborative Filtering をしていることになります。
では、アイテムの中身にもとづいてアイテムを選択する Content-Based Filtering で見るアニメを決めることはできるのでしょうか。アニメの「中身」とはそもそも何か?という問いは哲学的ですらありますが、私は NLP(自然言語処理) の研究を行っている(しがない)学生なので、自然言語で書かれたあらすじが「中身」の指標の一つとなるのではないかと思いました。
例えば、異世界転生系アニメのあらすじは、どの作品でも質的に似ているような気がします。また、異世界転生系のアニメのあらすじと日常系アニメのあらすじは、質的に異なるような気がします。こうした内容の近さ/遠さをモデルに学習させることで、「あまり知名度は無いけれど内容が似た作品」 を探すのに役立つのではないかという期待ができます。
質的に近いアニメのデータセットを構築するのは難しいように思えますが、幸いなことに、アニメのドメインでは教師なしで擬似的なラベルを得ることが出来ます。それは 一期、二期... のようなシリーズ関係 です。例えば『響け!ユーフォニアム』の一期と『響け!ユーフォニアム』の二期の近さと、『響け!ユーフォニアム』の一期と『ゾンビランドサガ』の二期の近さを比べた時、前者が後者よりも内容的に近いのは明らかでしょう。
この記事では、東北大の日本語BERTをベースとして、上述したシリーズ関係のペアをもとに Contrastive Learning(対照学習) *1 を行うことでモデルを fine-tuning します。そのようにして作成されたモデルからは、作品のあらすじの内容の近さを反映した埋め込み(ベクトル)が得られます。さらに、この得られた埋め込みを簡単に確認できるようにするため、可視化用のウェブサイトを立てました。
このサイトを使うことで、似た内容と推測されるアニメを簡単に調べることができます。例えば下図は『無職転生 〜異世界行ったら本気出す〜』に似た内容の作品を調べている画面です。右側には埋め込みの距離が近い作品が列挙されていますが、異世界ものが多くを占めていることが分かるのではないかと思います。

内容にもとづいて次に見るアニメを決める際に是非役立ててみてください。
データセットの構築
今回の実験では
- 一期、二期... のようなシリーズ関係にある作品のあらすじのペア
- 各作品のあらすじのデータ
が必要になります。これらは Annict から抽出することができます。
抽出のために書いたコードを貼っておきます。
シリーズ関係にあるペアの抽出
シリーズ関係にある作品のペアを抽出するコード · GitHub
結果として 559 件のユニークなシリーズ関係の作品ペアが得られました。 データ(JSONL)のファイルの行は例えば以下のような感じになっています。
{
"arasuji1": ["喫茶店ラビットハウスへやってきたココア。", "うさぎの看板に釣られて入ったこのお店こそが、彼女が下宿することになる場所でした。", "リゼや千夜、シャロたちとすぐに仲良くなったココアはすっかり“木組みの街\"の一員に。", "ラビットハウスの一人娘であるチノのことは本当の妹のように可愛いがっています。", "そうして迎えた二度目の夏。", "今年もチノたちと、たくさんの思い出を作りたいココアですが、", "神妙な表情で、キャリーケースを持って駅のホームにたたずんでいます。", "ココアはいったいどこへ……?", "マヤとメグも遊びに来てくれて楽しい時間が流れますが、", "ココアが抜けてどこかちょっぴり賑やかさの足りないラビットハウス。", "そんな中、チノは少しだけ勇気を出して、みんなを花火大会に誘ってみることにしたのでした。"],
"arasuji2": ["ココアが木組みの街で過ごす", "二度目の夏ももうすぐ終わり、", "季節はイベント盛りだくさんの秋へと", "移り変わろうとしています。", "学校にもラビットハウスにも、", "楽しいことが今日もいっぱい!", "ココア、チノ、そしてみんなの未来へのわくわくが止まりません……!"]
}
これは後で訓練用と validation 用に split します。
各作品の抽出
こちらは埋め込みの作成対象である作品一覧を抽出するコードになります。劇場版アニメや OVA 等は除いて、テレビアニメのみを対象としました。
ここで1つ残念なことが分かったのですが、Annict であらすじが登録されている作品は最近のものに限られるようです。実際、抽出された 836 作品の放映時期の分布は以下のようになりました。
| 放映時期 | 作品数 |
|---|---|
| 2022 | 17 |
| 2021 | 186 |
| 2020 | 146 |
| 2019 | 152 |
| 2018 | 161 |
| 2017 | 93 |
| それ以前 | 81 |
もし、2016年以前のアニメのあらすじを効率的に集める方法をご存知の方がいらっしゃいましたら、是非コメント等で教えてください。
Contrastive Learning
有識者の方はご存知かと思いますが、BERT のような大規模言語モデルから直接得られる埋め込みはタスクの役には立たないことが多いです。例えば、NLP において基本的なタスクの1つである STS(Sentence Textual Similarity) タスクにおいてもそうで、パフォーマンスを出すためには NLI データセットを用いて明示的に似た意味の文のペアを学習させないといけません。*2
アニメのあらすじに関しても、単純に日本語 BERT に通して埋め込みを得るだけではうまくいかないと考えられます。そこで、Contrastive Learning を行って、明示的に似た内容の作品ペアを学習させます。
具体的には、ある作品とそのペアの作品とのスコアが、訓練バッチ内の他の作品とのスコアよりも大きくなるように学習します。図にすると以下のような感じになります。赤い矢印同士のスコアが、青い矢印同士のスコアよりも高くなるようにするということです。
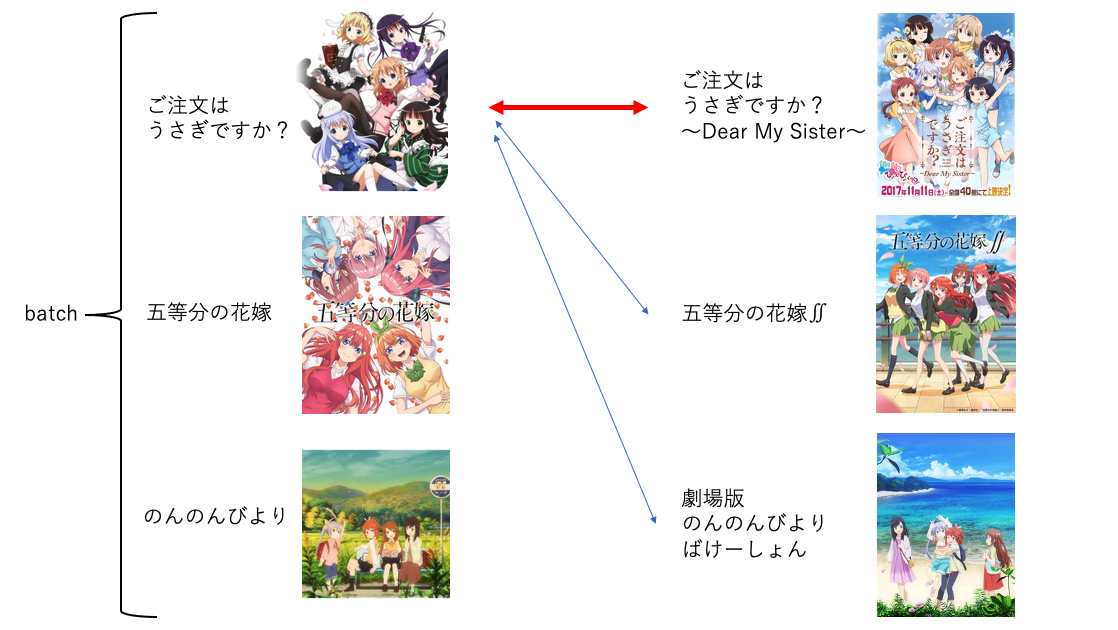
スコアの計算については、様々な流儀がありますが、今回は BERT の [CLS] トークンから得られる 768 次元の埋め込み同士の内積としました *3。
学習用コードは以下のようになります。
from accelerate import Accelerator from datasets import load_dataset import numpy as np import torch from torch.utils.data import DataLoader from transformers import AutoModel, AutoTokenizer, AdamW, default_data_collator, get_scheduler import argparse def main(args): accelerator = Accelerator() # データセットは shuffle 済みとする train_dataset = load_dataset('json', data_files=args.data_path, split='train[:90%]') valid_dataset = load_dataset('json', data_files=args.data_path, split='train[90%:]') tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking") model = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-whole-word-masking") def tokenize_function(examples): # 文区切り, または改行区切りの文章に対して, 間に [SEP] を挟んで連結する sentences1 = ["[SEP]".join(ex) for ex in examples["arasuji1"]] sentences2 = ["[SEP]".join(ex) for ex in examples["arasuji2"]] tokenized_arasuji1 = tokenizer( sentences1, padding='max_length', max_length=512, truncation=True, ) tokenized_arasuji2 = tokenizer( sentences2, padding='max_length', max_length=512, truncation=True, ) outputs = {} outputs["arasuji1_input_ids"] = tokenized_arasuji1["input_ids"] outputs["arasuji1_token_type_ids"] = tokenized_arasuji1["token_type_ids"] outputs["arasuji1_attention_mask"] = tokenized_arasuji1["attention_mask"] outputs["arasuji2_input_ids"] = tokenized_arasuji2["input_ids"] outputs["arasuji2_token_type_ids"] = tokenized_arasuji2["token_type_ids"] outputs["arasuji2_attention_mask"] = tokenized_arasuji2["attention_mask"] return outputs tokenized_train_dataset = train_dataset.map(tokenize_function, remove_columns=["arasuji1", "arasuji2"], batched=True) tokenized_valid_dataset = valid_dataset.map(tokenize_function, remove_columns=["arasuji1", "arasuji2"], batched=True) train_dataloader = DataLoader( tokenized_train_dataset, batch_size=8, collate_fn=default_data_collator ) valid_dataloader = DataLoader( tokenized_valid_dataset, batch_size=8, collate_fn=default_data_collator ) optimizer_grouped_parameters = [ { "params": [p for n, p in model.named_parameters()], "weight_decay": 0.0, }, ] optimizer = AdamW(optimizer_grouped_parameters, lr=5e-5) model, optimizer, train_dataloader, valid_dataloader = accelerator.prepare( model, optimizer, train_dataloader, valid_dataloader ) num_update_steps_per_epoch = len(train_dataloader) max_train_steps = args.num_train_epochs * num_update_steps_per_epoch lr_scheduler = get_scheduler( name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=max_train_steps, ) for epoch in range(args.num_train_epochs): model.train() for step, batch in enumerate(train_dataloader): arasuji1_outputs = model(**{ "input_ids": batch["arasuji1_input_ids"], "token_type_ids": batch["arasuji1_token_type_ids"], "attention_mask": batch["arasuji1_attention_mask"] }) arasuji2_outputs = model(**{ "input_ids": batch["arasuji2_input_ids"], "token_type_ids": batch["arasuji2_token_type_ids"], "attention_mask": batch["arasuji2_attention_mask"] }) arasuji1_embeddings = arasuji1_outputs[1] # take [CLS] embeddings arasuji2_embeddings = arasuji2_outputs[1] # take [CLS] embeddings scores = arasuji1_embeddings.mm(arasuji2_embeddings.t()) # contrastive learning bs = scores.size(0) target = torch.LongTensor(torch.arange(bs)) target = target.to("cuda:0") loss = torch.nn.functional.cross_entropy(scores, target, reduction="mean") accelerator.backward(loss) optimizer.step() lr_scheduler.step() optimizer.zero_grad() model.eval() eval_accuracy = 0.0 nb_eval_examples = 0 for step, batch in enumerate(valid_dataloader): arasuji1_outputs = model(**{ "input_ids": batch["arasuji1_input_ids"], "token_type_ids": batch["arasuji1_token_type_ids"], "attention_mask": batch["arasuji1_attention_mask"] }) arasuji2_outputs = model(**{ "input_ids": batch["arasuji2_input_ids"], "token_type_ids": batch["arasuji2_token_type_ids"], "attention_mask": batch["arasuji2_attention_mask"] }) arasuji1_embeddings = arasuji1_outputs[1] # take [CLS] embeddings arasuji2_embeddings = arasuji2_outputs[1] # take [CLS] embeddings scores = arasuji1_embeddings.mm(arasuji2_embeddings.t()) bs = scores.size(0) scores = scores.detach().cpu().numpy() predictions = np.argmax(scores, axis=1) target = torch.LongTensor(torch.arange(bs)).detach().cpu().numpy() tmp_eval_accuracy = np.sum(predictions == target) eval_accuracy += tmp_eval_accuracy nb_eval_examples += arasuji1_embeddings.size(0) normalized_eval_accuracy = eval_accuracy / nb_eval_examples print(f"epoch {epoch}: {normalized_eval_accuracy}") accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(f"output_epoch{epoch}", save_function=accelerator.save) if accelerator.is_main_process: tokenizer.save_pretrained(f"output_epoch{epoch}") if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("--data_path", type=str, required=True) parser.add_argument("--num_train_epochs", type=int, default=20) args = parser.parse_args() main(args)
手元で動かしてみたところ、4回目のepochで一番 validation accuracy が高くなったので、これを埋め込みモデルとします。
埋め込みの生成とウェブサイトのホスティング
モデルが作成されたところで、今度は、Annict にあらすじが登録されている 836 作品の埋め込みを作っていきます。これは、後でウェブサイトの形式に合わせるため TSV で保存します。
import torch from tqdm import tqdm from transformers import AutoModel, AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("./trained_model") model = AutoModel.from_pretrained("./trained_model") model.eval() import json with open("annict_data.jsonl", "r") as fi, \ open("embeddings_meta.tsv", "a") as fo1, \ open("embeddings.tsv", "a") as fo2: fo1.write("name\tseason\n") with torch.no_grad(): for line in tqdm(fi.readlines()): anime_data = json.loads(line) fo1.write(f"{anime_data['タイトル']}\t{anime_data['時期']}\n") arasuji_sentence = "[SEP]".join(anime_data["あらすじ"]) inputs = tokenizer.encode_plus( arasuji_sentence, padding='max_length', max_length=512, truncation=True, return_tensors="pt" ) outputs = model(**inputs) embeddings = outputs[1][0].detach().cpu().numpy() embeddings_str = [str(e) for e in embeddings] embeddings_str_concat = "\t".join(embeddings_str) fo2.write(f"{embeddings_str_concat}\n")
埋め込みの可視化サイトには https://github.com/tensorflow/embedding-projector-standalone を使います。これは既に github pages の形式になっているので、フォークして自分が作った埋め込みを代わりに載せてあげるだけで可視化ができ、とても便利です。
埋め込みの観察
では、作成された埋め込みを実際に見ていきましょう。
まず、全体を UMAP で可視化すると、2つの大きな塊群に分かれているように見えます。
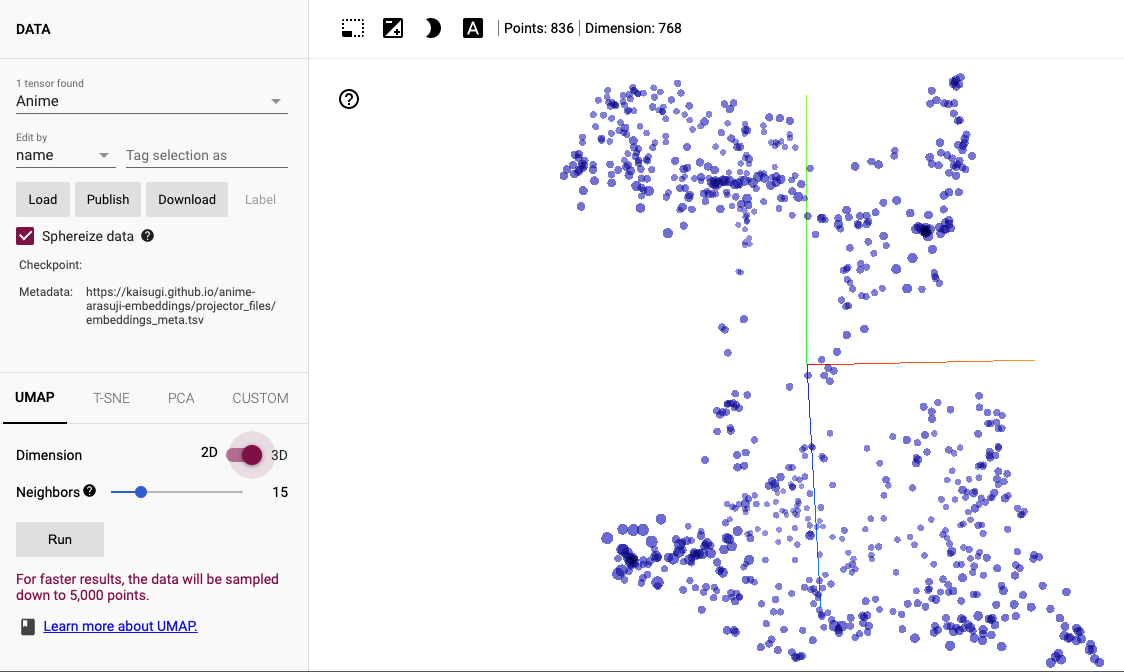
はっきりとした確証は持てていないのですが、自分の予想としては「日常系」作品と「非日常系」作品に分離しているのではないかと思っています。「日常系」作品のあらすじの方が「ゆるふわ」な言葉遣いであらすじが書かれている傾向にあることを考えれば、これは自然です。
具体的に近いアニメを探したい場合は、点をクリックすればよいです(Search のところから直接アニメのタイトルを検索することもできます)。
いくつか自分が知っている作品で調べてみます。

『ウマ娘 プリティーダービー』に最も近い作品は、シリーズ関係のものを除くと、『つうかあ』になりました。『つうかあ』はレーシングが題材のアニメなので、上手くサジェストできていると言えるでしょう。他にもアイマス関係が出てくるのも割と妥当な気がします。
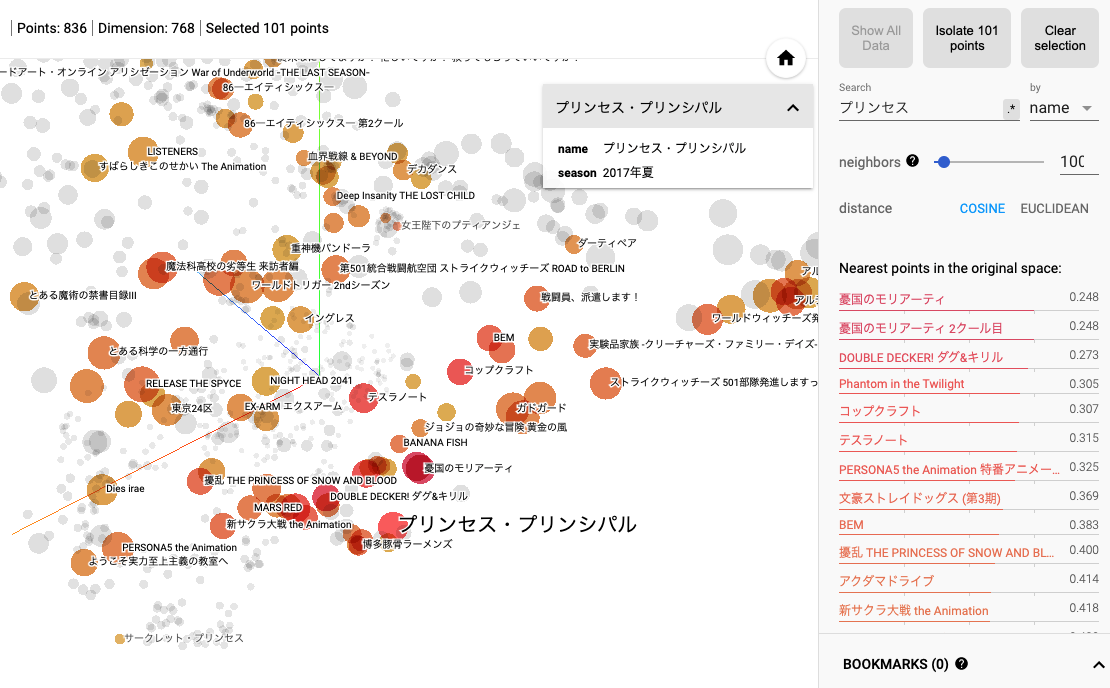
『プリンセス・プリンシパル』に近い作品としては、『憂国のモリアーティ』『DOUBLE DECKER! ダグ&キリル』『Phantom in the Twilight』などがサジェストされました。これらはいずれも、異国での探偵やスパイに関連する作品であり、内容にもとづいた推薦を行っていると言えそうです。
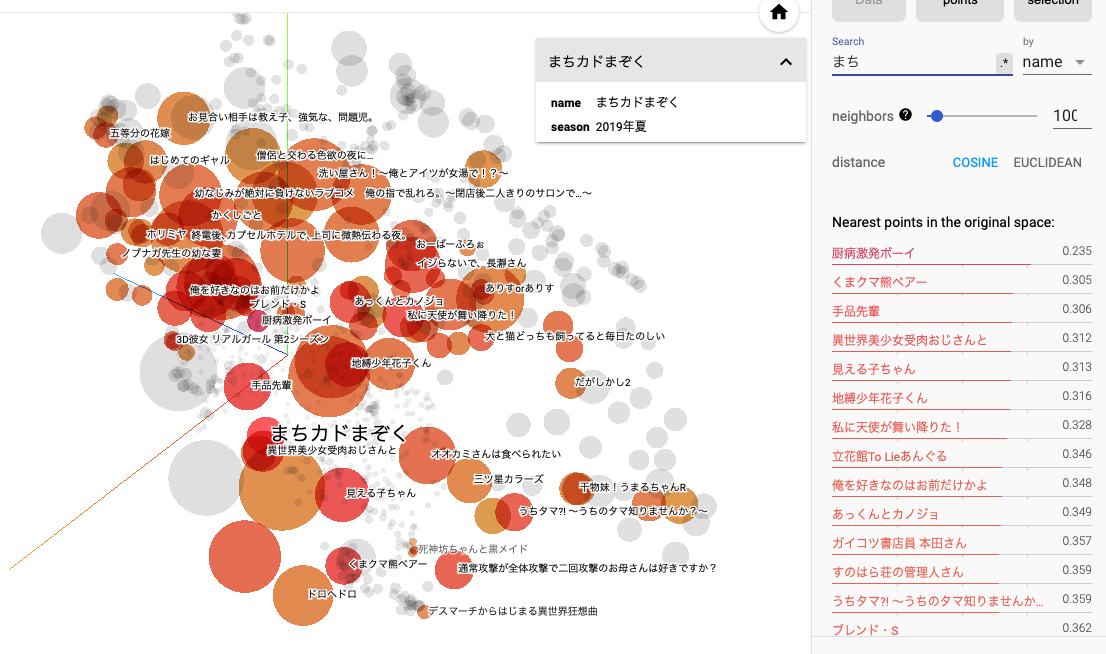
『まちカドまぞく』に近い作品としては、『厨病激発ボーイ』『くまクマ熊ベアー』『手品先輩』などがサジェストされました。全然知らない作品ばかりなので何もコメントできないのですが、一風変わった設定の日常系、くらいの共通項はあるのでしょうか...。
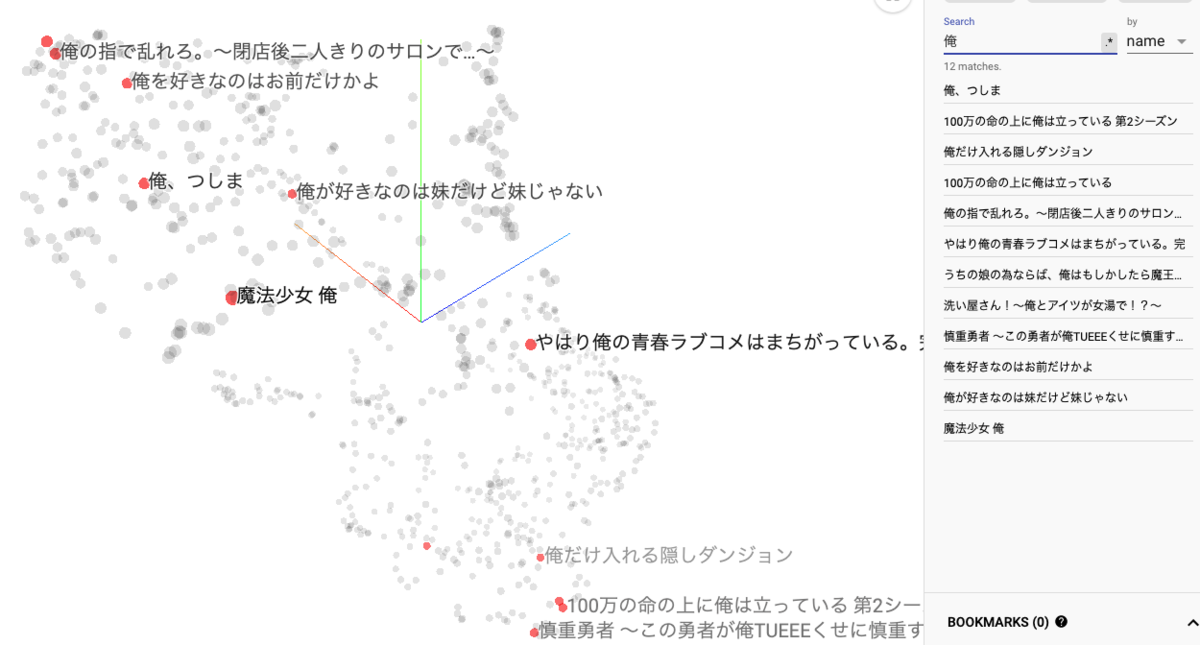
他にも、特定の文字をタイトルに含んだアニメだけに絞って埋め込みを観察するのも面白いです。例えば、以下は「俺」をタイトルに含むアニメの埋め込みを比較したものですが、質的な違いが相当あることが見てとれます(上の方が恋愛もの、下の方がなろう系。『俺ガイル』が真ん中あたりにあるのが面白いですね)。
おわりに
この記事では、機械学習を活用し、内容にもとづいて次に見るアニメを決める方法を紹介しました。あらすじはアニメの中身の要素のごく一部に過ぎませんが、一つの良い指標になるのではないかなと思います。
今は 2016 年以前の作品のあらすじをほとんど集められていませんが、今後も継続的にデータを増やして、より推薦候補作品を充実させていこうと考えています。